Tous les instituts de sondages qui ont opéré dans le cadre des élections présidentielles américaines se sont plantés. Certes les écarts étaient faibles, “dans la marge d’erreur” mais même les instituts penchant du côté républicain, à une exception près, donnaient généralement Hillary Clinton gagnante.
{kind=link}
Et les spécialistes de l’analyse prédictive basée sur le “big data” misaient eux aussi sur un succès de la candidate démocrate.
Bang! Le “Brexit puissance 3” que “prédisait” Donald Trump s’est produit. (Pour la petite histoire, relisez cette petite info – “Micro-ciblage électoraliste” – que nous avions publié dans notre rubrique “Snacks numériques du lundi“ sur le choix qu’avait fait le représentant du Parti républicain, pour sa campagne électorale sur réseaux sociaux, pour une société de neuromarketing britannique qui avait aussi agi en faveur de ce Brexit…)
Bang, disions-nous. La balance a penché du côté de Trump. Dans tous les Etats indécis. Que s’est-il passé? Décortiquons un peu ce plantage apparent de l’analyse big data. Apparent parce que le “big data”, ici, n’est pas celui que l’on croit.
Distorsions dans les sondages?
A 19 h 40, heure de New-York, le jour-même de l’élection américaine, David Rothschild, économiste de formation, chercheur en science prédictive, directeur de l’agence Predictwise et associé au Microsoft Research Group, publiait encore ceci: “7:40 PM ET: Clinton 90% after 7:30 PM closing. Clinton is closing up her firewall. Remember, she does not need Florida, North Carolina, or Ohio. Basically, everything is playing out as expected.”
En clair, il donnait encore Hillary Clinton gagnante, avec un degré de certitude de… 90%.
Que s’est-il passé? Comment expliquer ce ratage intégral?
Au lendemain des élections, Bruno Schröder, Technology Officer de Microsoft Belgique, émettait l’explication suivante: “l’un des éléments-clé à ne pas perdre de vue quand on parle et travaille sur le big data est la qualité des données. Sont-elles correctes et représentatives?”
La carte du rapport de forces Clinton-Trump, tel que prévue par Predictwise…
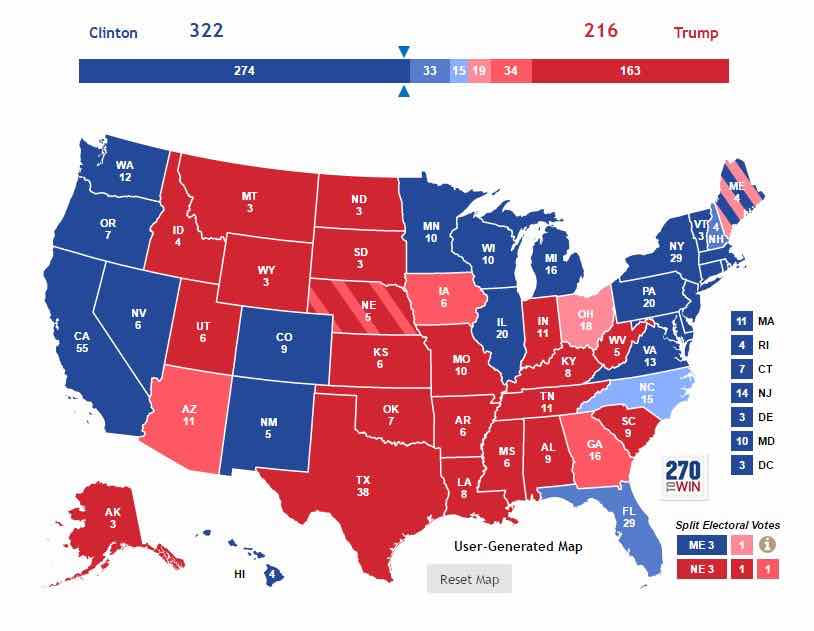{kind=link}
Les données qu’exploitent les instituts de sondage et celles qui alimentent les logiciels d’analytique prédictive sont-elles réellement “neutres”, “propres”, et surtout représentatives de la réalité?
Une partie de l’explication pourrait venir du fait que les données de base sur lesquelles moulinent les outils prédictifs ne sont en effet pas forcément neutres et représentatives. En raison, notamment, d’une sélection (inconsciente ou non) des échantillons de personnes sondées. Autrement dit, le panel ne serait pas réellement représentatif de la population. Parce que les sondeurs – et les analystes ? – sélectionnent des populations proches de leurs propres inclinaisons, ou qu’ils connaissent mieux? Ou parce qu’ils privilégient certains canaux: ligne téléphonique fixe, “oubliant” le mobile, Internet…? “Il y a un biais culturel chez les sondeurs”, estime Bruno Schröder. “La chose s’est encore manifestée lors du Brexit…”
Nombreux sont ceux qui pointent du doigt ce décalage entre les canaux de sondage utilisés et les médias que privilégient de plus en plus la population, avec des variations selon les catégories d’âge.
Larry Sabato, par exemple, professeur de sciences politiques à l’université de Virginie qui propose son propre site de statistiques (le “Larry Sabato’s Crystal Ball”, qui s’est d’ailleurs, lui aussi, “planté” lors de l’élection américaine), écrivait au lendemain du scrutin: “les sondages téléphoniques sont en perte de vitesse, souffrant à la fois d’une baisse du nombre de lignes fixes et du fait que les sondés ont de moins en moins envie de répondre à des questions par ce biais.” Selon lui, « la plupart des sondages seront faits à l’avenir en-ligne”.
Les sondages? Une image incomplète à géométrie variable.
Selon le moment où est mené le sondage, le taux et le “profil” des personnes qui ne désirent pas répondre – mais qui iront potentiellement voter – changent sensiblement. Ce qui, évidemment, impacte considérablement la qualité des données.
“Lorsque les nouvelles étaient bonnes pour Trump, ses supporters avaient davantage tendance à répondre aux sondages. Idem pour Clinton. Question restée sans réponse: où était le point d’équilibre?”, écrivait Andrew Gelman, statisticien et politologue américain, auteur du blog “Statistical Modeling, Causal Inference, and Social Science”.
Selon Bruno Schröder, le décalage entre habitudes de sondage et réalité de l’électorat a encore été amplifié, dans le cas des élections américaines, par le fait que l’électorat Trump est largement constitué de personnes rejetant l’establishment, le “système”, en “rupture fondamentale avec le système politique”, des personnes qui “échappent donc encore plus aux radars”. Mais qui se manifestent par contre devant les urnes…
Mais cela n’explique pas forcément le plantage de l’analytique big data qui, en principe, “ratisse” plus large que les échantillons et que les bases de données des instituts de sondage…
Et même si l’on accepte le raisonnement d’électeurs Trump ayant échappé au radar, une autre question se pose, sans réponse jusqu’ici: comment expliquer, si l’on reste dans une réflexion cartésienne, que ces électeurs “invisibles”, non pris en compte par les observateurs et analystes, se trouvent essentiellement du côté des blancs de la classe moyenne, déçus et “victimes” du système et de l’économie, bien plus que du côté des minorités “classiques” (Noirs, hispanos…)?
“Intriguant”
Le parfait contre-exemple de l’efficacité d’une prédiction big data vient donc de s’abattre sur tout le monde. La surprise est d’autant plus totale que les pronostics donnaient également Hillary Clinton gagnante dans un tout autre contexte que celui des instituts de sondage et sur lequel, justement, les outils prédictifs s’appuient pour se faire une idée plus exhaustive de la situation.
{kind=link}
“Un élément important que les prévisions de David Rothschild prennent également en compte est celui des paris”, indique Bruno Schröder. “Pour la plupart, les parieurs ne parient pas au hasard. Ils se renseignent et deviennent en quelque sorte des intégrateurs sociaux de données. En analysant le marché des paris et l’évolution des cotes, il est possible de voir quelles informations collectent une population [les parieurs] qui s’intéresse de près à un sujet précis.”
Nouvelle surprise, ici: les parieurs, eux aussi, se sont plantés. “Contrairement à ce qui s’était passé lors des élections antérieures…”
Ceci n’est pas du vrai “big data”
Pour Eric Delacroix, associé chez Eura Nova, il est primordial de ne pas mettre dans un même panier “big data” et statistiques. “Le premier principe repose sur l’apprentissage de schémas, de “patterns”, de contextes, de règles, de causes et conséquences, alors que le deuxième repose sur la base d’hypothèses. L’annonce de résultats de sondages ou d’études donne lieu à beaucoup de confusion parce qu’on ne précise pas clairement si les résultats évoqués sont issus d’un travail statistique ou analytique…”
“The system is rigged”
Donald Trump avait raison – mais pas comme il l’entend : le système est truqué. A la source.
Dans le contexte de ces élections américaines et de l’évaluation du travail des sondeurs, la question fondamentale – et la source du problème – est évidemment la “qualité” (fiabilité, représentativité…) des données.
“Comment contrer un mensonge”, s’interroge Philippe Dubernard, d’IBM. “Si une personne décide de ne pas livrer ses véritables intentions de vote, il est impossible de rectifier. Sauf si l’on se lance dans une analyse approfondie de la “personnalité” du sondé en comparant ses réponses au sondage avec son comportement sur les réseaux sociaux.” Mais c’est très difficile, tant l’être humain est à la fois unique et imprévisible.
{kind=link}
“Pour obtenir un “personality insight” valable, dans le cadre par exemple d’un recrutement, il faut par exemple pouvoir disposer d’un texte original, rédigé par la personne elle-même, comportant de 5 à 6.000 mots. Cela permet d’analyser la personnalité en se basant sur la tonalité, la résonance des mots…”
Eric Delacroix (Eura Nova): “Que peut-on tirer comme conclusion de ce résultat-surprise? Que les outils pour comprendre ce qui se passe ne se suffisent pas à eux-mêmes. Ils auront toujours besoin des humains pour en faire un bon usage!”
Associé chez Eura Nova, Eric Delacroix, lui aussi, soulignait l’écueil du mensonge, ou à tout le moins de la dissimulation des véritables intentions: “si aucune information n’est disponible sur le niveau de dissimulation d’une publication [Ndlr: publication sur un réseau social ou, de la même manière, dissimulation dans une réponse à un sondage], la machine la prendra pour information exacte.
En guise d’amuse-gueule…
Cela n’a rien à voir avec le big data, la qualité des données (ou des outils d’analyse) ou les instituts de sondage mais lisez cette opinion de l’économiste (pro-démocrate) Paul Krugman (“Comment truquer une élection”), publié sur le site de la Rtbf, qui explique comment la réalité peut être distordue et déboucher sur le scénario que nous venons de vivre cette semaine. Comment dit-on encore en langage informatique? “Garbage In, Garbage Out”?
Mea culpa de David Rothschild
Sur quelles données David Rothschild s’est-il basé? Il dit avoir utilisé à la fois des sources de données privées et publiques. Il a notamment testé une nouvelle méthode consistant à collecter des données via un sondage sur MSN et un autre, pour utilisateurs mobiles, via Pollfish.
“J’ai commis l’erreur de faire confiance aux sondages publics et de ne pas tenir compte des sondages privés. Les sondages réalisés via MSN (45 sur 51) pointaient tous vers une victoire de Donald Trump dans le Michigan et le Wisconsin tandis que les sondages via Pollfish le désignaient quasi invariablement comme vainqueur en Pennsylvanie.”
{kind=link}
Ces mêmes sondages, via de nouveaux canaux, révélaient une faiblesse dans les Etats de la “Rust Belt”.
Les sondages publics, eux, se sont plantés dans trois des Etats, à savoir le Michigan, le Pennsylvania et le Wisconsin, “alors qu’ils constituaient l’épine dorsale de ce qu’on a appelé le “pare-feu” d’Hillaty Clinton” [Ndlr: autrement dit, la ligne de défense dont elle pouvait se prévaloir contre la vague bleue de Trump].
La clé, selon David Rothschild, était la Pennsylvanie. Non pas uniquement en termes de chiffres mais parce qu’elle était représentative de la volonté des électeurs dans des Etats socio-politiquement similaires, à savoir la Floride, la Caroline du Nord et l’Ohio.
On sait ce qu’il en est advenu…
Au-delà des chiffres bruts…
Pour la petite histoire, certains avaient bel et bien prévu le basculement de ces Etats dans le camp de Trump. Non pas en s’appuyant sur des sondages, des statistiques ou des interprétations classiques mais en analysant le ressenti, les “sentiments” des électeurs potentiels… d’un point de vue plus psychologique (et là, la “machine” est encore loin de disposer de l’“intelligence” nécessaire). Relisez à ce sujet la tribune de Michael Moore, publiée… en juillet dans le Huffington Post (traduction française de la version originale, ici).
Un seul sondage a régulièrement “pronostiqué” la victoire de Donald Trump, en l’occurrence le sondage Daybreak du Los Angeles Times (partenaire de Dornsife, Université de Californie). Or, ce sondage a appliqué une autre technique, pondérant les chiffres bruts par le… “degré d’enthousiasme dont font preuve les personnes interrogées dans le soutien qu’elles apportent à leur candidat” (sur une échelle de 1 à 100).
{kind=link}
D’autres acteurs, eux aussi, ont pris en compte d’autres facteurs ou sources d’informations. Ainsi la société Spredfast, spécialisée dans l’analyse des réseaux sociaux, a analysé les sentiments qui s’exprimaient sur les réseaux sociaux à propos des candidats dans sept “swing states”. Spredfast a comparé la nature des tweets avec la réalité des votes. Elle s’est concentrée sur les contenus positifs des tweets afin de quantifier les tendances électorales en prenant soin d’éliminer certains twittos douteux. Par exemple, les comptes Twitter qui ont moins de 200 suiveurs, estimant que ce pourrait être le signe que ces comptes sont en fait des bots…
Caltech (le California Institute of Technology) est allé un peu plus loin… mais après l’élection. Le site Tweeting the Election analyse les tweets par zone géographique et en fonction de la couleur ou tendance politique de chaque twitto.
Prédiction à l’aveugle
L’une des raisons pour lesquelles les prédictions de Predictwise se sont avérées fausses est par ailleurs le fait que David Rothschild n’avait “aucune vue sur les décisions qui déterminent les choix de l’électorat et le support qu’il octroie à tel ou tel candidat.”
Après coup, voici les interrogations que sin ratage suscite en lui.
“Des sondages isolés peuvent-ils réellement déterminer l’électorat probable aussi bien que le permet une modélisation à partir de données historiques? Passaient-ils à côté d’électeurs blancs moins instruits?
Sans accès aux réponses individuelles, je ne disposais d’aucun moyen rigoureux pour procéder aux ajustements nécessaires.
{kind=link}
Les sondages sous-estimaient-ils le support en faveur de Trump de la part de Républicains ou de femmes blanches au degré de scolarité plus élevé?
Sans savoir comment les sondeurs pondèrent les réponses individuelles, je ne disposais d’aucun moyen rigoureux pour procéder aux ajustements nécessaires.
Par ailleurs, comment les sources d’erreur potentielles, dans les divers Etats, étaient-elles corrélées? Je ne veux plus jamais me retrouver dans une situation où je dois prédire une fenêtre de résultats combinatoire sans avoir accès aux données brutes sous-jacentes. […]
Je préférerais avoir accès à 100.000 réponses individuelles plutôt qu’à 10.000 chiffres agrégés de 1.000 personnes interrogées (soit 10 millions de réponses). Avec 100 fois moins de réponses, je peux discerner nettement plus de choses au sujet de la manière dont un électorat ressent les choses à propos d’un sujet précis, qui transformera ce sentiment en acte (en l’occurrence, en vote) et discerner quelle est la corrélation de ces estimations à travers divers groupes démographiques.”
Il dit en tout cas en avoir tiré les leçons et vouloir se concentrer dans les prochains mois sur de nouvelles recherches et sur la validation de sa nouvelle méthode incluant des sondages “2.0”.
David Rothschild (Predictwise): “Je ne veux plus jamais me retrouver dans une situation où je doit prédire une fenêtre de résultats combinatoire sans avoir accès aux données brutes sous-jacentes.”
Selon lui, il est impératif de composer un cocktail de données plus large et plus varié et de mieux prendre en compte le degré d’incertitude – ou d’imprévisibilité, si vous préférez.
“Si l’on aborde le problème comme si l’on se trouve dans un contexte de market intelligence, nous devons en conclure qu’il nous faut développer des stratégies qui se concentrent sur la collecte non seulement d’informations portant sur le citoyen lambda – comme le font les sondages nationaux – mais qui puissent réellement comprendre les spécificités démographiques détaillées (exemple: blanc/outre-collège électoral/Wisconsin).
{kind=link}
Cela n’est pas uniquement valable pour une période d’élection mais aussi, dans ce monde toujours plus personnalisé, pour l’ensemble du marketing. Lorsqu’on vous dit que la marge d’erreur est de plus ou moins 3, pensez plutôt + 7/- 7…”
Autre problème lors des élections: les spécificités démographiques, Etat par Etat, ont insuffisamment été prises en considération.
Et, dans ce domaine, les modèles de sondage appliqués par le Comité national du Parti républicain, lui-même, se sont plantés: ils avaient prévu une défaite de Trump en Pennsylvanie, en Floride, dans le Wisconsin et l’Iowa. Or, il a fini par les emporter (du moins si le nouveau comptage des votes, qui vient d’être demandé, ne vient pas à nouveau rebattre es cartes…)
“Dans un monde toujours plus personnalisé, que ce soit en politique ou en marketing de manière générale, la marge d’erreur n’est de plus ou moins 3, mais plutôt de + 7/- 7… ” Parce que les échantillons de sondage ne sont pas suffisamment représentatifs de la population. Et parce que le moment où est pratiqué le sondage n’est jamais neutre: des raisons multiples, tenant aux réactions aléatoires, psychologiques ou comportementales, amèneront des réponses biaisées ou un refus de répondre.
Le défi des réseaux sociaux
Cette incapacité à juger de la validité des réponses aux sondages — ou encore la manière dont les sondeurs les “interprètent” [aux Etats-Unis, 4 sondeurs s’appuyant sur des données identiques ont publié des estimations différentes] — s’applique aussi à l’analyse des publications sur les réseaux sociaux. Comment déterminer si ce qui s’y dit, écrit et propage est authentique, honnête ou au contrairement factice et biaisé? Volontairement ou non?
Un chiffre a de quoi faire perdre totalement confiance: une quantité non négligeable de posts ayant trait aux élections américaines ont été générés par… des bots, des scripts automatiques. Bonjour la distorsion de réalité !
David Rothschild: “Il est temps d’aller au-delà de la simple agrégation de résultats au départ des sondages publics pour inclure une nouvelle génération de collecte de données et d’analyse.”
Par ailleurs, quel impact ont les réseaux sociaux, la perception que l’on a de l’avis de la majorité des gens, l’impression de ne pouvoir échapper à l’effet moutons de Panurge? Question quasi-existentielle mais qui s’applique aussi au sujet qui nous occupe.
Voici comment l’exprime Eric Delacroix, associé chez Eura Nova, centre d’expertise en analytique basé à Mont-Saint-Guibert. “Aujourd’hui, la foi de certains en une analyse peut les pousser à se désolidariser du choix qui doit être fait : pourquoi dire ce que l’on pense si de toute façon tout le monde pense le contraire, voire si de toute façon tout le monde pense la même chose?
Par ailleurs, est-ce que chaque diffuseur de sondage le fait avec la même objectivité? Et enfin, est-ce que tout le monde est à même de comprendre la méthodologie utilisée? Si rien de tout ça n’est explicable en toute transparence, il y a fort à parier que tout puisse être dit ainsi que son contraire. L’éducation est primordiale.”
Découvrez-nous sur Facebook
Suivez-nous sur Twitter
Retrouvez-nous sur LinkedIn
Régional-IT est affilié au portail d’infos Tribu Médias.