Chercheur depuis 2010 au MIT Media Lab et plus précisément au laboratoire Human dynamics, Yves-Alexandre de Montjoye y mène des travaux de recherche sur la modélisation comportementale sur base des métadonnées personnelles, afin d’analyser les mouvements humains, les mécanismes d’influence et les schémas de communications dans les réseaux sociaux.
{kind=link}
Ces recherches et son projet openPDS/SafeAnswers ont attiré sur lui les projecteurs. De quoi le faire figurer parmi les lauréats du concours Innovators under 35 organisé par le MIT Technology Review.
Ses travaux se focalisent essentiellement sur les thèmes suivants:
- les lacunes de l’anonymisation des données personnes
- et la manière de protéger la vie privée des individus.
Le mirage des données anonymisées
En 2013, une équipe du MIT a démontré combien les techniques d’anonymisation des données étaient précaires et peu concluantes, n’évitant aucunement les risques d’identification d’un individu.
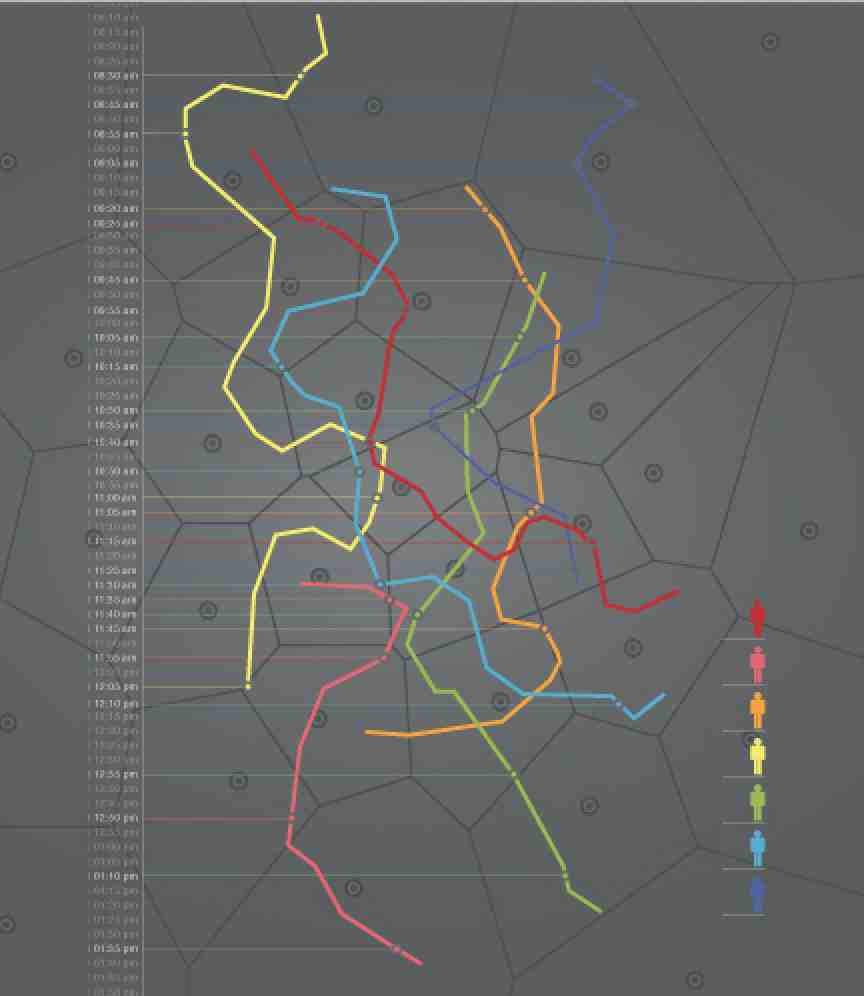
Quatre éléments d’informations, sur l’usage qu’il fait de son téléphone, suffisent à identifier n’importe quel mobilonaute. Source: MIT.
{kind=link}
Les données de téléphone portable sont particulièrement faciles à réidentifier. “Il suffit d’avoir 4 points – 4 endroits et le moment où vous y étiez. Statistiquement, dans 95% des cas, vous êtes la seule personne qui a pu être à ces 4 endroits aux moments concernés. Cela démontre combien il est difficile d’obtenir une réelle anonymisation des données “riches” comme le sont par exemple des données de carte de crédit.”
Les recherches de l’équipe du MIT ont également démontré que même, en réduisant la “résolution” spatiale et temporelle (en travaillant sur des zones géographiques et des plages de temps plus larges), on ne résout pas le problème de ré-identification. Celle-ci est certes plus difficile à réaliser mais reste possible. Il suffit d’ajouter quelques points supplémentaires.
Au-delà de cette problématique, poursuit Yves-Alexandre de Montjoye, il y a la question de ce que peut-on inférer, prédire d’un individu sur base de ces données. “On a réalisé un proof of concept en regardant comment une personne se comporte, appelle, envoie des SMS, en n’utilisant que les métadonnées. On sait que tel utilisateur a procédé à un appel, à tel moment, vers une personne inconnue. On sait qu’il vous a envoyé un SMS, qu’on ne connaît pas, qu’il a passé deux minutes et demi au téléphone avec une personne… Sur cette base, on peut prédire sa personnalité, son profil BFI (Big Five Inventory).”
Le BFI est un test psychologique qui distingue 5 profils – neurotism, extraversion, conscientiousness, agreeableness, openness.
{kind=link}
L’équipe du MIT a démontré que l’analyse des données de téléphonie d’un individu permettaient d’inférer son profil, son type de personnalité. Non pas tant les données “brutes”, telles que l’identité des correspondants, mais bien les données “comportementales” portant sur la manière dont un individu utilise son portable.
Une série de 36 indicateurs sont en fait retenus: longueur des appels, type d’utilisation (appel, sms…), fréquence, régularité, diversité des personnes contactées, moments d’utilisation… Selon la manière dont ils se combinent, sont corrélés, dans le comportement d’utilisation d’un individu, il devient possible de “profiler” ce dernier.
Autrement dit: difficile, voire impossible, de se prémunir et de protéger ce qu’on a de plus personnel contre les oreilles et yeux indiscrets.
Ne pas jeter le bébé avec l’eau du bain
Ces constats ayant été posés, démontrés scientifiquement, Yves-Alexandre de Montjoye ne préconise pas pour autant l’abstinence numérique. Comme il le disait dans l’entretien qu’il nous a accordé (relire notre article), les données sont d’une phénoménale utilité mais la modération s’impose.
Ses recherches visent donc à trouver un moyen de protéger la vie privée par d’autres voies que ces techniques d’anonymisation qui ne fonctionnent pas en réalité. La collecte constante, non différenciée, de toutes nos données est surdimensionnée et inutile, professe-t-il. Pourquoi accepterait-on que toutes nos informations sur l’endroit précis où nous sommes allés tout au long d’une année, minute par minute, soient nécessaires pour répondre à des questions parfois simples, du genre: analyse des causes d’un embouteillage, un certain matin d’octobre, sur un tronçon précis du ring de Bruxelles?
C’est la raison d’être du projet OpenPDS/SafeAnswers.
Cette solution que propose Yves-Alexandre de Montjoye et ses collègues chercheurs du Media Lab se compose de deux éléments.
D’une part, l’OpenPDS (Personal Data Store), un “data store” sécurisé, référentiel de données personnelles, où chaque individu peut stocker, centraliser ses métadonnées de mobilité, données transactionnelles (achats, opérations bancaires…) et données dites “contribuées” (sur réseaux sociaux, via les applis mobiles, générées par des capteurs de fitness…). Grâce à cet espace personnalisé, lui appartenant en propre, chaque individu contrôle les accès à ses métadonnées (selon le principe de l’opt-in), ne les autorisant que selon des principes clairs, potentiellement différents selon l’identité et les finalités du requérant (chercheur, service public, opérateur commercial…).
{kind=link}
L’idée – l’espoir – de base? Qu’en permettant à tout un chacun d’avoir accès (et la maîtrise) à ses données personnelles, on lui permette aussi de (mieux) comprendre et de mieux gérer les risques que portent en elles ou suscitent les données collectées. “L’utilisateur peut alors réellement contrôler le flux de données et gérer des autorisations d’accès à granularité fine.”
La solution openPDS a déjà franchi le pas du commercial puisqu’une spin-off du MIT se chargera de sa commercialisation.
Il s’agit de la société ID3. Cette jeune pousse développe une version cloud de l’openPDS; les “personal data stores” pourront donc être hébergés dans le cloud, dans un premier temps sur des serveurs situés aux Etats-Unis – “et donc encore accessibles à des tiers, tels la NSA”, soulignait notamment la revue New Scientist dans un article. Mais les opérateurs et autres “collecteurs” ne seront plis les les seuls à pouvoir par exemple accéder et exploiter les données de géolocalisation d’un individu. Ce dernier, lui aussi, y aura droit…
Le même article du New Scientist signalait par ailleurs qu’openPDS est par exemple déjà utilisé à l’hôpital Massachusetts General Hospital. Objectif: protéger la vie privée des patients, dans le cadre d’un programme baptisé Catch. Divers paramètres sont surveillés en permanence (taux de glucose, température, rythme cardiaque, activité cérébrale…). Des données analytiques sont également relevées via des applis installées sur des smartphones (humeur du patient, activités, liens sociaux…). Explication du directeur du département médecine de l’hôpital: “nous voulons pouvoir étudier les données médicales de personnes bien réelles, en temps réel et dans la vie réelle, d’une manière qui ne viole pas leur vie privée.”
Deuxième volet de la solution: SafeAnswer.
“SafeAnswers propose un mécanisme très simple de questions-réponses. L’objectif est de permettre à divers acteurs – des chercheurs, une ville qui désire comprendre pourquoi un embouteillage se forme à telle heure… – d’utiliser les métadonnées auxquelles l’utilisateur donne accès. On ne procède pas par anonymisation. On octroie plutôt un accès aux métadonnées. La requête “mouline” sur ce jeu restreint de métadonnées au lieu de farfouiller dans des méga-jeux de données prétendument anonymisés (mais, comme on l’a vu, pouvant être assez aisément réidentifiées).
Yves-Alexandre de Montjoye: “Uniquement les informations que vous acceptez de partager seront partagées.”
{kind=link}
Yves-Alexandre de Montjoye reprend l’exemple de la malaria qu’il avait cité dans notre entretien. “Celui qui tente de dégager une tendance, des enseignements d’un jeu de données pourra créer un morceau de code qui posera un certain nombre de questions. On demande ainsi à l’usager s’il a été à Nairobi, à proximité de telle antenne, s’il s’est rendu près du Lac de Victoria, pour combien de nuits… Sur cette base, on peut reconstruire le modèle, poser des questions pour chaque individu, sans jamais devoir avoir accès aux données brutes.”
Transposons le scénario chez nous.
“Au lieu que ce soit toutes les applications qu’on a par exemple installées sur son GSM qui collectent et envoient systématiquement des données qui seront ensuite analysées, on fait en sorte que ce soit l’utilisateur qui collecte lui-même les données qui lui sont fournies par une banque, un opérateur téléphonique… ou qu’il a collectées lui-même via des capteurs, pour qu’il puisse donner accès à ces données pour répondre à une question très précise.
La partie qui veut procéder à une analyse doit donc obtenir l’autorisation de la personne. Le code sera alors envoyé à la personne et une réponse en sortira: moyenne d’argent dépensé dans tel magasin, manière dont vous répartissez votre budget mensuel … Uniquement les informations que vous acceptez de partager seront partagées. Par exemple, êtes-vous d’accord de me dire que vous étiez sur le ring, que vela vous a pris 15 minutes. Par contre, vous ne seriez pas d’accord que, pour répondre à cette simple question, on collecte les données de géolocalisation pendant un mois…”
Une illusion de chercheur?
Ce concept ne peut toutefois marcher qu’à condition que les détenteurs de données et ceux qui veulent en faire usage (qui ne sont pas forcément les mêmes) acceptent de demander l’autorisation des individus avant de les exploiter. Et précisent la finalité de l’analyse.
Selon Yves-Alexandre de Montjoye, on se dirige de toute façon dans cette direction. Il cite notamment en exemple la dernière directive européenne de protection des données qui impose que, pour des données personnelles, il y ait un contrôle par l’utilisateur de l’usage qui est fait de ses données.
D’un point de vue technique, l’objectif est d’isoler les données brutes de l’usage qui en est fait et, ensuite, de remettre l’utilisateur au centre de processus d’exploitation des données.
“A l’avenir, plus on démontrera qu’on ne peut pas réellement anonymiser les données, les utiliser sans qu’on puisse potentiellement les relier à l’individu, plus on se rendra compte qu’il faut trouver une autre manière de pouvoir utiliser ces données tout en protégeant la vie privée. En Europe, on s’oriente de plus en plus vers le concept de droit de regard de l’utilisateur sur l’usage qui est fait de ses données. Cela pourra prendre diverses formes. Par exemple, un opérateur demandera à l’utilisateur s’il accepte que la ville de Bruxelles ou le SPF Mobilité accède à ses données pour répondre à une certaine liste de questions. L’utilisateur pourrait collecter lui-même ses données et les mettre ensuite à disposition. Etc. etc.
L’idée est d’un point de vue technique d’isoler les données brutes de l’usage qui en est fait et, ensuite, de remettre l’utilisateur au centre de processus d’exploitation des données. C’est lui qui a le droit d’accéder à ses données brutes et de décider comment elles seront utilisées. Cela permet aussi de simplifier les choses parce qu’il est très difficile de comprendre ce qui peut être fait des données brutes.
{kind=link}
C’est plus simple si c’est l’utilisateur qui peut déterminer ce qu’il est prêt à divulguer: oui, j’étais sur le ring et j’ai mis 15 minutes pour parcourir 5 km en raison d’un accident, plutôt que d’accepter que l’on connaisse tous les endroits où il a été pendant une semaine, juste pour répondre à cette même question…”
“Trouver la meilleure façon de pouvoir utiliser les données en préservant la vie privée de l’utilisateur.”
Il n’empêche que le défi n’est pas gagné, que de nombreux obstacles demeurent. Tout le monde devra jouer le jeu, tant ceux qui collectent les données (souvent à notre insu), ceux qui veulent les exploiter – et ce ne sont donc pas toujours les mêmes, et ceux qui les génèrent (les utilisateurs eux-mêmes). Les “questionneurs” devront demander l’autorisation d’accéder et de traiter les informations. Chaque individu devra gérer – finement – les accès à ses données. Et non plus laisser les portes et fenêtres ouvertes à tout-va, comme c’est le cas aujourd’hui, ou – c’est là une tendance qui semble vouloir prendre de l’importance – envisager de vendre ses données, mêmes les plus privées et sensibles, à des tiers, de confiance ou non, moyennant rétribution.
Autre question à laquelle il n’y a pas encore de réelle réponse à l’heure actuelle: si chaque individu possède et veille jalousement sur son propre “data store” OpenPDS, pourra-t-il lui-même l’“exploiter”, en tirer des enseignements, par exemple pour améliorer ses chances de rester en bonne santé, minimiser les pertes de temps dans les embouteillages ou mieux gérer son budget personnel? Pourra-t-il inférer, à son niveau, ce que les données brutes signifient par rapport à sa personnalité, ses tendances et/ou ses prédispositions? Lors d’une interview donnée en 2013 à l’occasion de son passage en France (colloque Big data organisé par l’Institut des Systèmes complexes et l’Ecole Normale Supérieure de Lyon), Yves-Alexandre de Montjoye reconnaissait qu’un individu ne dispose pas des outils lui permettant de distinguer dans la masse de ses données personnelles celles qui peuvent lui permettre de caractériser son comportement, de définir son profil BFI. Comprendre les données n’est pas à la portée de tout un chacun. Mais, indiquait-il alors, “on peut avoir l’espoir que les chercheurs développent des algorithmes équivalents à ce qui se fait déjà commercialement, un peu comme la communauté open source développe des logiciels équivalents, sinon supérieurs, à ce qui se fait commercialement…”
Découvrez-nous sur Facebook
Suivez-nous sur Twitter
Retrouvez-nous sur LinkedIn
Régional-IT est affilié au portail d’infos Tribu Médias.