La “lecture” des petits cailloux blancs numériques que nous semons à tous vents au gré de nos déambulations, physiques ou virtuelles, quotidiennes peut révéler quelques surprises. Chaque “moment” (un coup de fil via smartphone, un achat, une consultation Internet géolocalisée, un paiement électronique…) trace non seulement la carte de nos déplacements mais aussi dessine le portrait de nos habitudes, comportements et préférences.
{kind=link}
Refrain bien connu. Mais a-t-on réellement conscience de ce que certaines de nos données personnelles, en apparence anodines et indolores, peuvent réellement permettre de déduire de qui nous sommes?
En ce début d’année, plusieurs médias, à commencer par le New York Times, auteur de l’article qui a allumé la mèche, se sont fait l’écho de résultats, plutôt perturbants, obtenus par des chercheurs de l’université californienne de Stanford. Les données Google Street View – vous savez celles qui cartographient nos rues pour des déplacements plus aisés et qui sont théoriquement anonymisées (floutage des visages, plaques et autres signes distinctifs) -, ces données Street View permettraient de déterminer avec un degré de pertinence plutôt élevé… nos préférences électorales.
En tout cas est-ce le cas outre-Atlantique…
50 millions d’images et moi et moi et moi (émoi)
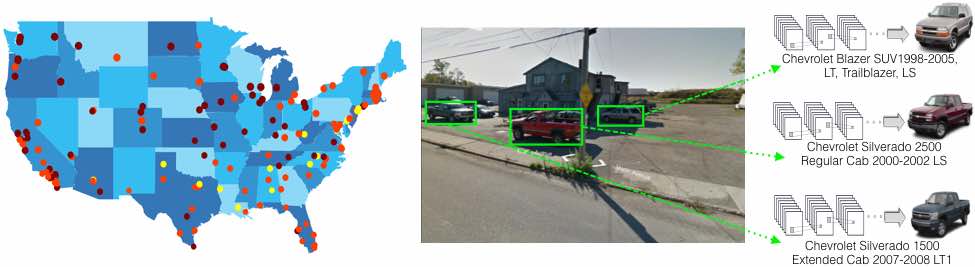
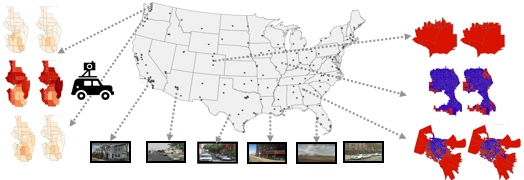
Une équipe de chercheurs du laboratoire d’intelligence artificielle de l’université de Stanford (1) s’est servie des données visuelles de Google Street View (50 millions d’images collationnées pour les besoins de l’étude) afin d’induire certaines informations sociologiques ou sociodémographiques, comme le niveau de revenus ou d’éducation, la race, le degré de pollution mais aussi… les préférences politiques. De quoi ouvrir la voie à une nouvelle manière de prédire le vote des habitants.
La méthode utilisée? Identification des modèles de voitures (22 millions de véhicules ont été répertoriés dans quelque 3.000 zones postales et 39.000 circonscriptions électorales), classement en catégories “signifiantes” (2.657 catégories de véhicules) et analyse via croisement avec d’autres sources de données publiques, notamment les statistiques de l’American Community Survey et la base de données Precinct-Level Election Data (élections présidentielles de 2008).
Désormais, lorsque vous déambulerez dans les rues de l’Amérique, vous aurez un marotte de plus pour passer le temps: repérer le type de voitures qui y circulent ou y sont garées pour prédire les résultats des prochaines élections. Davantage de berlines? Les Démocrates l’emporteront (probabilité de 88%). Plutôt des pick-ups à cabine allongée? Le balancier penchera du côté républicain (probabilité de 82%).
Source: Etude de l’équipe de Stanford “Using deep learning and Google Street View to estimate the demographic makeup of the US”.
{kind=link}
Le fait de tirer certaines conclusions du type de voiture que vous conduisez n’a bien entendu rien de nouveau. Voici déjà de nombreuses années, on savait par exemple que si vous croisiez une Volvo sur une route américaine, il y avait de fortes chances qu’une femme soit au volant. La marque avait en effet construit une image de fiabilité et de sécurité qui séduisait davantage la gent féminine.
Ce qui est par contre nouveau et interpelant pour l’avenir de notre “sphère privée”, ce sont des déductions d’ordre très personnel que l’on tire de l’analyse de big data croisées. Pas sûr que le libre arbitre, en matière de choix (politiques, notamment), résiste longtemps à cette nouvelle “transparence”…
Conclusion? N’oubliez pas de rentrer votre voiture au garage 🙂
________
(1) L’équipe de chercheurs est dirigée par Timnit Gebru, doctorante au Stanford Artificial Intelligence Laboratory, dans le cadre d’une spécialisation en vision assistée par ordinateur. Elle effectue en fait un post-doctorat chez Microsoft Research à New York, au sein du groupe FATE (Fairness Transparency Accountability and Ethics in AI). Ces travaux sont en partie financés par le programme DARE (Diversifying Academia, Recruiting Excellence) de Stanford et par le programme de bourse GRPF (Graduate Research Fellowship Program) de la NSF Foundation. Fil rouge de ses travaux de recherche: l’exploitation de masses de données publiques disponibles en vue d’en extraire des informations de nature sociologiques et de résoudre les problèmes de vision assistée par ordinateur qui leur sont associés.
Composition de l’équipe de chercheurs: Timnit Gebru, Jonathan Krause, Yilun Wang, Duyun Chen, Jia Deng, Erez Lieberman Aiden et Li Fei-Fei. [ Retour au texte ]
Découvrez-nous sur Facebook
Suivez-nous sur Twitter
Retrouvez-nous sur LinkedIn
Régional-IT est affilié au portail d’infos Tribu Médias.