Spécialisée dans la prestation de services réglementaires en matière de protection des données à caractère personnel et, de manière encore plus spécifique, pour les besoins d’acteurs du monde des sciences de la vie (sociétés pharmaceutiques, CRO, start-ups…), la société montoise MyDataTrust s’est lancée, en partie grâce à un financement de la Région wallonne (voir notre encadré en fin d’article), dans le développement d’une solution devant lui permettre de proposer à l’avenir un “Data Protection Canvas”, dans la perspective ce qu’elle appelle des “augmented data protection services”.
{kind=link}
Objectif: cartographier en quelque sorte les raisonnements développés par les spécialistes humains – juristes et responsables de la protection des données -, identifier, documenter, structurer et systématiser les connaissances dans le domaine (textes légaux, avis de juristes…) et s’appuyer sur l’intelligence artificielle pour automatiser certaines tâches.
En amont, un travail minutieux d’identification et de caractérisation des différentes tâches, de leur complexité, de la fréquence avec laquelle elles doivent être effectuées par des analystes, consultants et autres DPO (data protection officers) comme le sont ceux de MyTrustData. Caractéristique des consultants de la société montoise: il s’agit pour beaucoup de professionnels de la recherche clinique formés à la protection des données à caractère personnel.
“Le but est à la fois de systématiser l’approche et de nous permettre d’augmenter notre capacité d’intervention pour un niveau de ressources humaines constant”, indique Hubert Stoop, chief innovation officer de MyDataTrust.
Des ressources rares, pas forcément disponibles au sein des acteurs du monde de la recherche clinique, dont le temps et les compétences sont précieuses mais monopolisées par des tâches de vérification de conformité souvent très primaires et contraignantes… Par exemple, la vérification de l’adéquation de données purement administratives ou l’analyse des formulaires de consentement..
“Quatre défis à relever”
Le projet de MyDataTrust prendra forme en plusieurs étapes. “Le développement de l’application et de la plate-forme implique pour nous de relever quatre défis”, explique Hubert Stoop. “Le premier consiste dans la centralisation des informations [informations que les consultants de la société ont eu à connaître au gré de leurs missions en clientèle], des décisions [légales et juridiques] et des échanges intervenant entre les différentes personnes dans le cadre d’une mission de conseil en protection et en mise en conformité RGPD.”
{kind=link}
Rien qu’à ce niveau, les défis voire obstacles sont de taille et certaines lignes rouges devront être judicieusement gérées.
Au niveau des données, par définition sensibles, collectées et gérées pour les clients (pour rappel, acteurs de la chaîne des essais cliniques), “une muraille de Chine doit être respectée entre les données des différents clients.” La “centralisation” de ces données devra donc évoluer sur une ligne de crête pour n’autoriser qu’une “porosité” judicieuse, les mécanismes d’analyse automatisée devant “se nourrir” d’un maximum de données pour être efficaces, tout en se limitant à des informations “communes et non sensibles”.
Même expérience d’équilibriste en termes de “centralisation des décisions”. “Comment centraliser l’intelligence quand certains éléments des réglementations évoluent parfois dans une zone grise, laissant place à de l’interprétation?”, relève Hubert Stoop. Interprétations pouvant varier d’un juriste à l’autre… “Il faudra donc veiller à une sorte d’unicité de telle sorte qu’à contexte égal, les décisions prises par les collaborateurs soient toujours les mêmes”, souligne-t-il.
Hubert Stoop (MyDataTrust): “Une application basée sur l’intelligence artificielle pour faire face au défi du recrutement et du partage de connaissances…”
Deuxième étape: l’élaboration d’un mode de représentation des flux de données, de leur cheminement, de l’adéquation des contenus – représentation qui soit compréhensible et abordable.
“Idéalement, une seule page, un seul écran, devrait représenter l’état de la protection des données dans le cadre d’une étude clinique”. Une interface graphique rendant ainsi visibles les processus d’échanges et les flux impliquant par exemple hôpitaux, laboratoires, CRO… dans le cadre d’un essai clinique donné, et prouvant leur adéquation. “Le but est de s’assurer que les échanges sont conformes et sécurisés entre tous les maillons de la chaîne et d’identifier clairement et rapidement, en les visualisant, les risques et failles dans les relais entre les différents intervenants.”
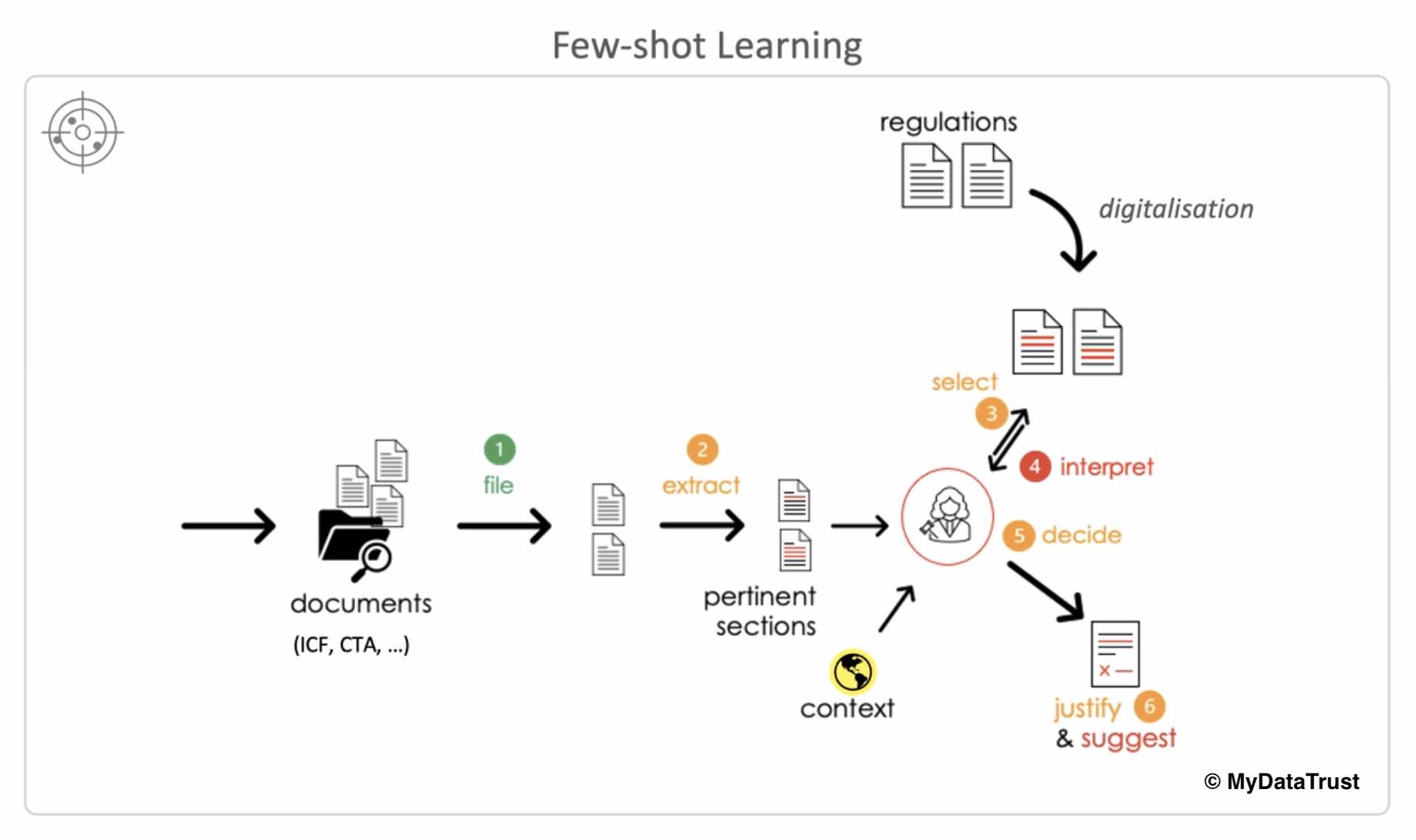
Viendra ensuite l’étape de l’Intelligence Artificielle. “C’est le défi le plus important.” Une IA qui sera chargée de classifier les documents (ICF-informed consent form, CTA-clinical trial application,…), en extrayant notamment l’information utile et pertinente au départ de documents en tous genres (courriels compris), de les glisser dans le dossier client adéquat, d’en extraire les informations significatives… Du genre, noms, adresse, points de contact… “Cette procédure est aujourd’hui effectuée manuellement par nos consultants, tâche peu gratifiante pour eux! L’IA nous permettra ainsi de gagner du temps.”
{kind=link}
A ce stade, MyDataTrust dit déjà avoir développé un prototype fonctionnel.
Autre rôle confié à l’IA: extraire, au départ des documents, des sections pertinentes relatives à une réglementation et déterminer quels contrôles doivent être effectués en fonction de la nature de ce “terreau”. Enfin, des mécanismes d’IA effectueront une corrélation entre contenu et réglementations, pour vérifier – simple exemple – que l’ICF comporte bel et bien les coordonnées du DPO de l’établissement. Ou, autre exemple, déterminer si les documents disponibles sont conformes à la réglementation ou à son interprétation.
Mais pour les rôles les plus “pointus”, estime Hubert Stoop, “l’IA n’opérera qu’en suggestion. L’interprétation et la décision finales demeureront encore longtemps le rôle et la responsabilité d’un être humain…
Quatrième et dernier défi: goupiller une “expérience utilisateur” qui soit simple, abordable.
Le calendrier? Une première version, disposant des potentiels de base, est planifiée dès la fin de cette automne. Avec arrivée de fonctionnalités complémentaires (évaluation et analyse des informations de registre, production automatique de rapports – notamment pour l’analyse d’écarts de conformité…) prévue au printemps ou à l’été 2023. Le contrôle automatisé de documents, lui, ne serait réalisable que d’ici un an, moyennant un nouveau financement à obtenir de la Région afin de financer les travaux de chercheurs de l’UCLouvain… (voir encadré ci-contre).
Pour les besoins de ce projet, MyDataTrust a recours à des compétences, plus spécifiques, d’autres acteurs: B12 Consulting pour les développements logiciels et l’intégration de l’Intelligence Artificielle, l’université de Namur pour un support en expertise légale et l’UCLouvain, notamment pour les compétences de ses départements ILC (Institut du Langage et de la Communication) et Cental (traitement du langage).
Des chercheurs spécialisés de l’UNamur interviendront par exemple pour la labellisation des documents (bonne dose de juridique oblige) afin de pouvoir déterminer si la “matière” dont se nourrit le moteur IA, pour son entraînement continu, sont bel et bien conformes aux dispositions légales et réglementaires en vigueur.
Pour ce qui est de la démarche IA, MyDataTrust, avec l’aide de B12 Consulting, combinera diverses techniques: active learning, meta learning, continuous learning – dans une démarche dite de “few shot learning” permettant un apprentissage automatisé qui se contente de jeux de données moyennement importants – “l’IA a généralement besoin de gros volumes de données pour devenir performante. Or, MyDataTrust ne dispose que de quelque 2.000 documents de départ. D’où cette technique de faibles jeux de données…”
{kind=link}
RGPD et au-delà
Si les services prestés et la future solution automatisée visent essentiellement les contraintes du RGPD, la plate-forme se veut évolutive et adaptable à d’autres réglementations – existantes ou à venir. On peut citer ici le Data Protection Act britannique, le Swiss Data Protection Act, l’HIPAA américaine et la future réglementation US qui se dessine tout doucement outre-Atlantique en matière de privacy, ou encore la directive européenne NIS-2.
Changement de modèle
L’avènement de cette plate-forme technologique va par ailleurs modifier en profondeur la manière dont la société propose et facture ses interventions. Finie la tarification à l’heure. Voici venir la tarification en mode SaaS (de la prestation “as a service”).
Dans un premier temps, la solution ainsi développée servira à MyDataTrust elle-même et à ses consultants. A terme, l’espoir est de pouvoir la mettre à disposition, en mode SaaS, à des sociétés et acteurs, en ce compris ceux et celles qui, aujourd’hui, ne sont pas clients de la société montoise.
A son niveau, la mise en oeuvre de la solution automatisée devrait – c’est son espoir – “augmenter sa productivité de 40%. De quoi supporter notre croissance.”
Hubert Stoop prend un exemple: “dans l’état actuel des choses, l’élaboration d’un dossier d’analyse pour des transferts de données intervenant entre deux pays différents prend de l’ordre de la demi-journée. Avec la solution, le délai sera réduit de moitié.”
Quant à l’étape de vente de la plate-forme, paramétrable, à des tiers, la tarification se fera donc en mode SaaS et abonnement mensuel. Premier domaine d’activités visé: toujours les essais cliniques. “Mais avec possibilité, grâce aux qualités de paramétrisation et d’adéquation à diverses réglementations de la plate-forme, de viser à terme d’autres secteurs…”
Financement du projet
Pour financer la réalisation de son projet, MyDataTrust a eu droit à une aide financière de la Région wallonne en deux volets. D’une part, une subvention pour recherche industrielle, couvrant la moitié du budget pour ce poste (aide de quelque 373.000 euros sur un total de plus de 500.000 euros). D’autre part, une avance récupérable de 830.000 euros, octroyée pour les besoins du développement de logiciel, et couvrant là aussi un peu plus de la moitié du budget total.
Le solde du financement est assuré par MyDataTrust elle-même.
A noter que MyDataTrust n’a pas attendu de recevoir le financement public pour se lancer dans le développement de la solution. Celui-ci était déjà largement entamé lorsque la société a reçu l’imprimatur du ministre responsable (Willy Borsus) en juin de cette année. Avec signature de la convention fin août…
A noter encore au passage qu’à l’été 2021, le fonds privé d’actions de croissance TechLife Capital, centré sur les secteurs de la santé et des tech, est entrée au capital de MyDataTrust, à hauteur de 20%.
Découvrez-nous sur Facebook
Suivez-nous sur Twitter
Retrouvez-nous sur LinkedIn
Régional-IT est affilié au portail d’infos Tribu Médias.