Le SMCS, service de conseils en analyse de données et statistiques de l’UCLouvain, inaugure, en collaboration avec le Cental (Centre de traitement automatique du langage), une nouvelle formation dédiée au Text Mining en Python.
{kind=link}
La formation se déroulera au mois de juillet, sous forme de “cours d’été”, du 8 au 12 juillet à Louvain-la-Neuve.
En guise de hors-d’oeuvre ou de préparation, une initiation au langage Python sera proposée les 4 et 5 juillet. Accessible à tous, cette initiation est toutefois plus particulièrement destinée à ceux et celles qui s’inscriront pour la formation en text mining.
Pour quel public?
La formation s’adresse aussi bien à des personnes ayant un profil scientifique qu’à un public d’entreprises.
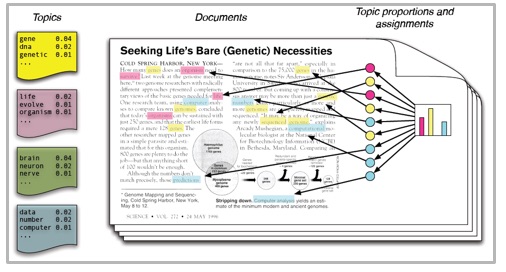
Pourquoi s’intéresser plus particulièrement au text mining? “Le traitement automatique du langage et, notamment, le text mining [analyse et exploration de texte] font aujourd’hui partie intégrante de notre quotidien. Moteur de recherche de Google, application Siri d’Apple, assistant personnel Alexa d’Amazon en sont des exemples. La structuration de l’information et l’analyse du contenu sont essentielles pour extraire des dates ou des horaires dans des courriels afin de planifier un événement, pour identifier les actions à effectuer suite à une commande vocale…”
Mais le champ d’application est encore bien plus vaste: “le text mining recouvre des techniques variées qui permettent, par exemple, d’automatiser la veille stratégique, d’analyser le style d’un auteur ou d’identifier les sentiments exprimés sur Internet à propos d’un événement, d’un produit…”
{kind=link}
Quant au langage Python, il a été privilégié pour cette formation dans la mesure où “il devient l’un des langages de référence en data science.”
La formation, qui s’appuiera sur des exemples concrets, sera organisée en cinq modules:
– pré-traitement des données textuelles: collecte et normalisation de documents, identification des éléments de contenu pertinents, associer à différentes métadonnées
– étiquetage automatisé d’informations linguistiques
– calculs de similarité entre documents, via représentation vectorielle ou techniques plus avancées (méthodes à base de réseaux de neurones…)
– techniques de classification
– découverte des concepts théoriques liés à l’analyse syntaxique et application à des opérations d’extraction et de structuration d’événements financiers (prise de participation, fusion, acquisition, etc.).
Pré-requis: “une bonne connaissance de la programmation en général”. Des connaissances de base en Python sont un plus mais, comme signalé, une remise à niveau sera possible les 4 et 5 juillet.
Informations supplémentaires et inscriptions via le site du SMCS.
Découvrez-nous sur Facebook
Suivez-nous sur Twitter
Retrouvez-nous sur LinkedIn
Régional-IT est affilié au portail d’infos Tribu Médias.