Eura Nova, société de services et centre de recherche spécialisé en gestion, en optimisation stratégique ou infrastructurelle, en architectures, modèles, analyse et exploitation de données, a franchi un pas de plus dans son catalogue d’activités en lançant récemment une solution de type “data lake” qui, un jour, pourrait faire l’objet d’une spin-out.
{kind=link}
“Digazu” (né sous le nom de code de David, pour Data Architecture Vision – Implementation Details), est une solution de traitement temps réel des données, plus spécifiquement du big data, qui tend à scénariser et à accélérer les “cas d’utilisation” analytiques les plus fréquents au sein d’une (moyenne ou grande) entreprise.
Premier cas d’utilisation visé: la création accélérée de jeux de données ou de mixage de sources, à destination des data scientists.
Si le nom de code DavID avait une logique (DAV étant l’acronyme de Data Architecture Vision et ID signifiant Implementation Details de cette architecture DAV), d’où vient le nom commercial – Digazu – qui a finalement été choisi?
Ce nom fait en fait référence… aux chutes d’Iguazu, situées en pleine forêt tropicale sud-américaine, à la frontière entre l’Argentine et le Brésil. Il s’agit donc d’une allusion, voire d’une allégorie, aux flux intenses de données.
“Les use cases les plus fréquents et prioritaires sont souvent des classiques. Exemple-type dans le secteur bancaire: l’évaluation de solvabilité des clients ou l’analyse du phénomène d’attrition (churn)”, souligne Eric Delacroix, associé chez Eura Nova. “Et dans la majorité des cas, ce genre d’analyse requiert de 60 à 80% des données dont dispose la société. Chaque use case implique de jongler avec un minimum de dix tables. A chaque fois, il y quelques différences. Mais les problèmes que pose la mise en oeuvre de ces traitements sont toujours les mêmes: coût élevé et complexité de l’acquisition des données, mises à jour, cohérence, suivi de l’utilisation qui est faite des données…”
Le fait est que les données, toujours plus volumineuses, d’origines diverses, sont aujourd’hui “malaxées” et utilisées dans une foultitude grandissante d’usages, par des utilisateurs aux profils, besoins et objectifs toujours plus disparates: analyse prospective, aide à la décision, production de rapports, injection dans une panoplie d’applications…
D’où l’idée d’Eura Nova de proposer aux entreprises (d’une certaine taille) une solution qui simplifie au maximum l’écheveau en mode spaghetti et qui évite de reproduire indéfiniment les mécanismes de connexion vers les différentes sources de données et les opérations de filtrage, sélection, transformation, rechargement de base de données, scénarisation de l’acheminement…
Autre but recherché en créant Digazu: “éviter de toucher sans cesse aux bases et systèmes opérationnels, quel que soit le nombre de requêtes et d’utilisateurs concernés au fil du temps.”
Sources, lac et robinets
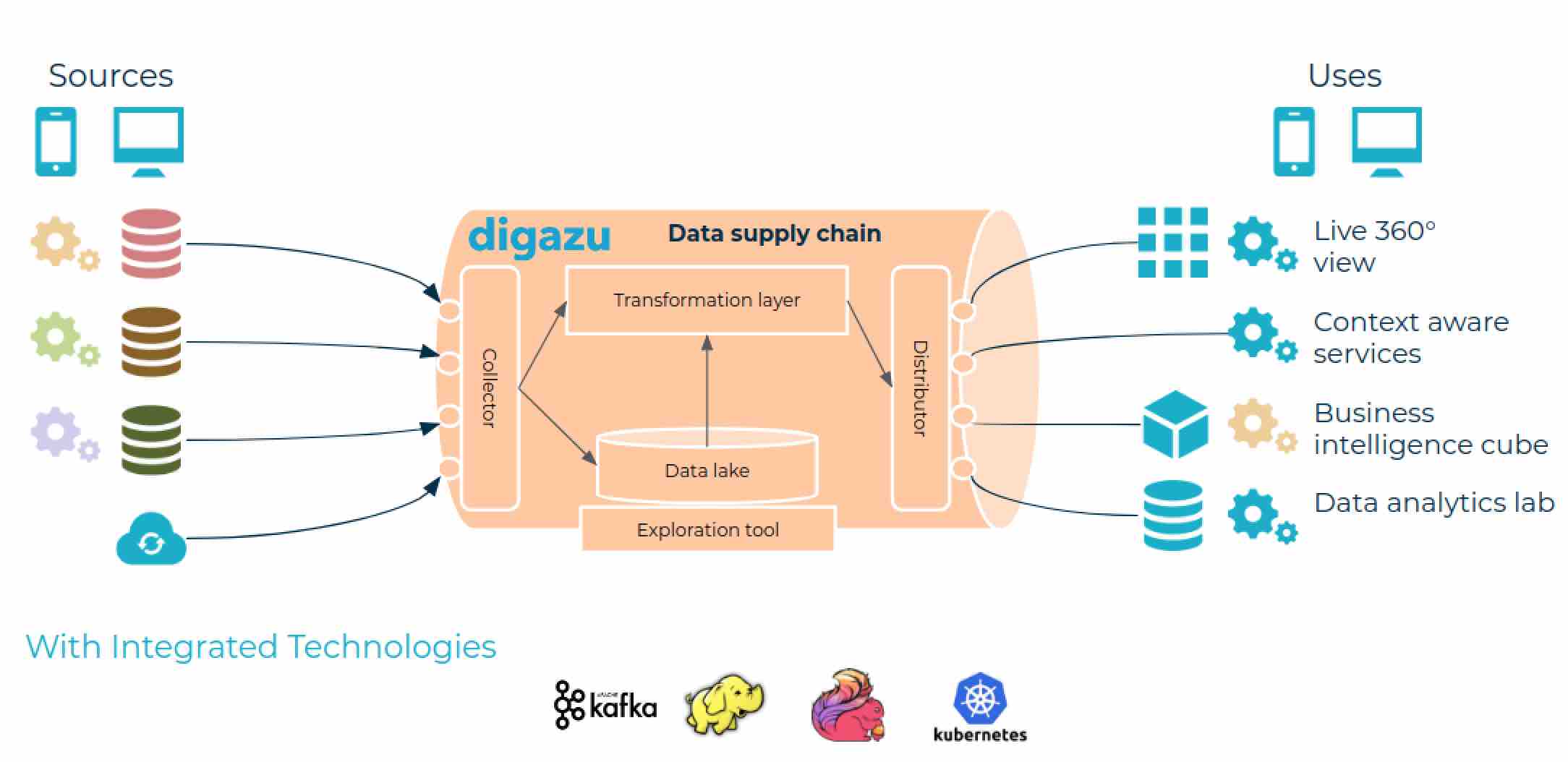
Pour le définir de la manière la plus simple possible, Digazu est un orchestrateur de flux de données et une solution de type data lake, dotée de mécanismes réitérables, visant les opérations en amont et en aval.
Digazu commence par constituer un catalogue de sources de données, propre à chaque entreprise. Une fois ces sources répertoriées et les connecteurs créés, la solution imaginée par Eura Nova accélère la collecte des données résidant dans diverses bases de données opérationnelles ou venant de sources diverses (en ce compris externes), dans la mesure où les mécanismes d’accès et d’ETL (extract, transform, load) ne doivent plus être répétés.
{kind=link}
La plate-forme assure les transformations nécessaires, injecte les données, les stocke et les gère dans le “data lake”, et, sur base des besoins spécifiques, les (re)distribue vers les applications et systèmes qui en feront différents usages.
“Plus besoin, pour chaque use case nouveau de se préoccuper de savoir où se trouvent les données dont on a besoin et de répéter les processus ETL. Il suffit de piocher dans la bibliothèque constituée par Digazu”, explique Eric Delacroix.
Chaque utilisateur a droit à sa bibliothèque de transformations ou de filtres à appliquer aux données opérationnelles (tel typologie de client, telle valeur de contrat…). C’est également dans Digazu que la destination des données est définie et que les data scientists, par exemple, lancent leurs requêtes, après avoir créé leurs modèles analytiques. Par exemple, telle sélection de contrats actifs pour tel profil de client sera injectée dans un outil de production de rapport.
Eric Delacroix (Eura Nova): “La définition de la stratégie des use cases et des scénarios de connexion incombe toujours à la direction des entreprises. Avec Digazu, Eura Nova intervient pour construire la stratégie technologique, la tuyauterie et pour proposer les compétences en termes de data science.”
Le data lake, lui, est alimenté en continu, mis à jour en temps réel au fur et à mesure que les données situées dans les bases de données opérationnelles ou dans d’autres réservoirs de données sont elles-mêmes réactualisées ou modifiées.
Ce schéma implique bien évidemment de constituer un énorme réservoir de données, ce qui représente un coût en termes d’infrastructure de stockage, mais, raisonne Eura Nova, c’est là un coût bien moindre, devant lequel les moyennes et grandes entreprises ne rechignent pas. Il ne représente en effet qu’une fraction du coût de leurs projets analytiques. Et, par ailleurs, argument majeur des concepteurs de Digazu, les économies réalisées en termes de préparation et d’implémentation de use cases compensent largement le coût engendré par la constitution du data lake.
Un data lake géré
Digazu revendique l’appellation de lac de données outillé. Outre les différents mécanismes et répertoires automatisant la collecte et les flux de données en amont, la plate-forme dispose en effet de mécanismes de traçabilité de l’usage qui est fait des données: utilisation des données, à quelle fin, suivi des différentes transformations, gestion des droits et politiques d’accès aux données, génération de rapports d’audit, tests et validation de la qualité des données…
“La plate-forme assure le suivi constant de l’utilisation qui est faite des données. Qui a créé le filtre, qui a sélectionné les données, quelle transformation a été appliquée. Cela permet de limiter les droits d’action de chaque utilisateur, d’éviter de distribuer des informations vers des personnes non autorisées…”
Pour ce faire, Digazu assure une intégration étroite avec la couche de gestion des métadonnées ainsi qu’avec des outils de gestion de la qualité des données.
Garder la main sur les données
Digazu est une solution qui se déploie sur site, au sein de l’infrastructure interne d’une entreprise – pour rappel, la solution se destine à de moyennes et grandes entreprises qui doivent définir et gérer de multiples use cases.
{kind=link}
“Une société qui n’aurait qu’un ou deux use cases n’aurait sans doute aucun intérêt à utiliser notre solution, compte tenu du coût de l’architecture, de l’infrastructure et du stockage. A moins que l’on puisse imaginer et appliquer un modèle de facturation intéressant…”, déclare Eric Delacroix.
Pas de chiffre cité mais une précision néanmoins: la tarification appliquée par Eura Nova est “liée à la valeur qu’on parvient à créer, en fonction du nombre de use cases”.
Autre question: pourquoi avoir choisi de proposer Digazu sous la forme d’une solution que l’on implémente et déploie en interne et non dans le cloud? “C’est la volonté actuelle des entreprises qui en sont les utilisateurs logiques. Essentiellement pour des raisons de gouvernance de données. Elles désirent garder la main sur leurs données. Autre raison: les performances. Déployer en interne évite les latences.”
Premiers POC
La solution Digazu a été déployée chez un premier client (secteur de l’assurance), en mode POC. Un premier use case doit permettre de convaincre la direction de l’intérêt – en ce compris économique – de ce “data lake orchestré”. Si tout se déroule favorablement, la mise en production pourrait intervenir début 2019.
D’autres clients se sont dits intéressés. “Souvent, ils nous contactent pour que nous les conseillions et leur expliquions en quoi leurs choix antérieurs en matière de gestion et d’exploitation de données n’étaient pas optimaux, en quoi ils s’étaient fourvoyés et pourquoi Digazu serait une solution plus pertinente…”
Lancée en juin, la première version de Digazu s’habille encore d’une interface de type SQL classique mais une version visuellement plus conviviale est en préparation. Et Eura Nova promet un ajout de nouvelles fonctionnalités toutes les six semaines (parmi les fonctionnalités planifiées: une intégration avec des systèmes de gouvernance de données et de sécurité de type RBAC- contrôle d’accès basé sur les rôles).
Dans un premier temps, la société s’est par ailleurs focalisée sur le scénario “création accélérée de jeux de données” ou de mixage de sources. Destinataires: les data scientists. Fonctions “coalisées” par la plate-forme Digazu? Sélection des données dans les sources préalablement identifiées, opérations de filtrage et de jointure, exportation des jeux de données…
{kind=link}
“Les data scientists étaient pour nous une priorité parce qu’ils peinent à trouver le chemin des bonnes sources de données. Le but, avec Digazu, est de permettre de rassembler le données, de les exploiter et de les mettre plus facilement en production…”
D’autres “packaging” répondant à d’autres usages concrets suivront: exploitation temps réel, visualisation des données en temps réel dans des rapports décisionnels (Business Intelligence)…
Dernière précision: le projet David/Digazu a fait l’objet d’un co-financement entre Eura Nova et la Région wallonne qui a octroyé au projet un financement sous forme d’avance récupérable couvrant un peu plus de la moitié du budget global (3 millions d’euros).
Découvrez-nous sur Facebook
Suivez-nous sur Twitter
Retrouvez-nous sur LinkedIn
Régional-IT est affilié au portail d’infos Tribu Médias.