Alimentée par l’analytique et l’IA, l’ère de l’intelligence procure une opportunité inédite pour le secteur du stockage. Les données sont devenues la nouvelle “monnaie” tandis que nous, les acteurs du secteur, nous pouvons en devenir les gardiens et régisseurs.
{kind=link}
Et pourtant, nous avons jusqu’ici empêché les entreprises de réaliser des progrès grâce aux données. Les architectures traditionnelles, telles que les silos et les lacs de données, ont été construites afin d’enfermer les données. Elles ne peuvent réaliser la seule chose nécessaire pour concrétiser la pleine valeur des données: les partager.
Le lac de données est condamné. Il a été imaginé sur le précepte dépassé selon lequel toutes les données non structurées sont destinées à être stockées. Aujourd’hui, dans l’ère post-lac de données, une nouvelle norme de stockage est nécessaire. L’intelligence moderne requiert une infrastructure conçue non seulement pour stocker des données mais pour les partager et les prodiguer. Nous appelons cette nouvelle architecture un “data hub”.
Lacs, silos, noeuds
Il est facile de replacer dans sa juste perspective l’importance qu’il y a à “potentialiser” les données, à les mettre à l’oeuvre. Une étude récente, menée par Baidu, a démontré que les jeux de données de la société devaient être multiplié par 10 millions en vue de réduire le taux d’erreur de son modèle linguistique et le faire passer de 4,4 à 3,4%. (1)
{kind=link}
Dix millions fois plus de données pour un gain d’un pour-cent! Le professeur Andrew Ng de l’Université de Stanford, une sommité en matière d’intelligence artificielle, relevait que “les données, et non pas le logiciel, sont l’“enceinte défendable” [l’avantage concurrentiel] pour de nombreuses entreprises (2) et que les entreprises “doivent unifier leurs entrepôts de données” (3).
Cet appel appuyé à unifier les données vise le coeur du problème. Les données sont engluées dans une profusion de silos. Et le secteur du stockage en est largement le responsable. Lorsqu’un secteur se focalise à ce point sur le développement de technologies visant à stocker les choses, il engendre tout naturellement des silos. Mais dans notre monde actuel, celui du “data first”, les silos s’avèrent contre-productifs. Les données sont hors de portée des applications modernes qui ont la faculté de procurer de nouvelles perspectives et de favoriser l’innovation.
Il est temps de repenser le stockage. Un “data hub” est conçu selon des principes premiers, non seulement pour stocker les données mais aussi pour les unifier et les fournir. Unifier les données signifie que de multiples applications peuvent accéder simultanément aux mêmes données, en garantissant l’intégrité totale desdites données. Fournir les données signifie que chaque application dispose de toute la performance d’accès aux données dont elle a besoin, à la vitesse qui est celle des activités d’aujourd’hui. Le “data hub” abat les barrières infrastructurelles traditionnelles, où les applications disposent de leurs propres silos et de jeux de données répliqués.
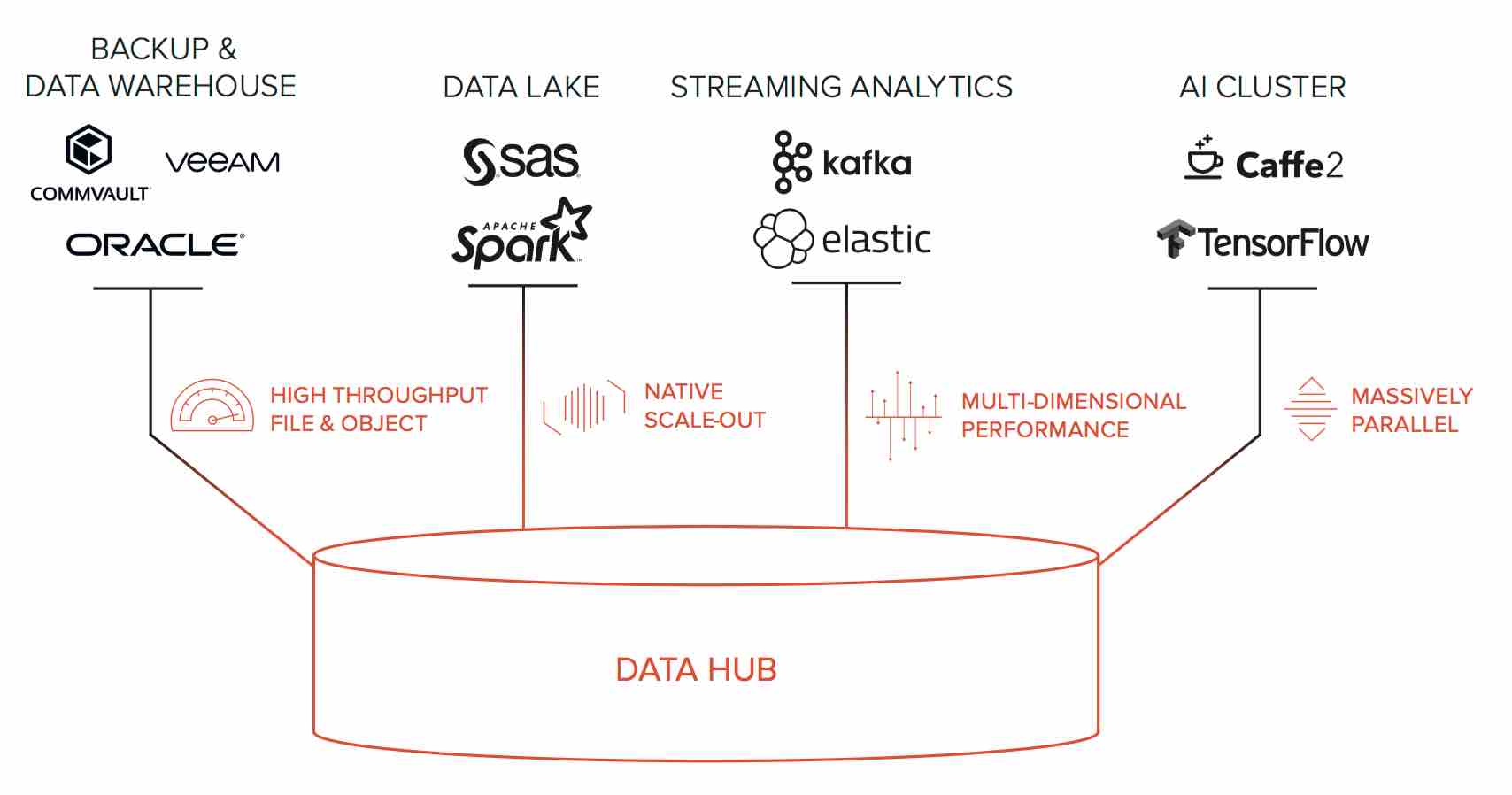
Le “data hub” est une architecture de stockage centrée sur les données qui alimente l’analytique et l’intelligence artificielle. Son architecture est basée sur quatre éléments fondamentaux:
- débit élevé pour les “magasins” de fichiers et d’objets
- conception évolutive (“scale out”) native
- performances multi-dimensionnelles
- architecture massivement parallèle.
Quatre caractéristiques indispensables
On dénombre quatre classes de silos dans le monde de l’analytique contemporain: les entrepôts de données, les lacs de données, l’analytique en continu et les grappes IA. Un entrepôt de données requiert des débits massifs. Les lacs de données procurent une architecture de stockage de type “scale-out”. L’analytique en continu va au-delà du modèle de traitements différés sur lac de données, nécessitant des ressources de stockage pour procurer des performances multi-dimensionnelles quelle que soit la taille (petite ou grande) des données ou quel que soit le type d’I/O (aléatoire ou séquentiel). Les grappes IA, animées par des dizaines de milliers de coeurs GPU, exigent que le stockage soit lui aussi massivement parallèle, desservant des milliers de clients et des milliards d’objets sans goulots d’étranglement.
A cela s’ajoute le cloud. Les applications sont de plus en plus conçues d’office pour le cloud, imaginées selon une architecture qui se base sur l’hypothèse selon laquelle l’infrastructure est dés-agrégée et l’espace de stockage illimité.
{kind=link}
Un “data hub” doit cumuler ces quatre qualités. Toutes sont essentielles pour l’unification des données. Un “data hub” peut disposer d’autres fonctionnalités, telles que des snapshots ou de la réplication, mais si l’une quelconque de ces quatre fonctions fait défaut à une plate-forme de stockage, celle-ci n’a pas été pensée et conçue de telle sorte à faire face aux défis actuels et aux possibilités futures. Si, par exemple, un système de stockage délivre des fichiers en haut débit et a été conçu, nativement, en mode “scale out” mais a besoin d’un autre système procurant un support objet S3 pour des charges de traitement conçues d’office pour le cloud, dans ce cas l’unification des données est rompue et la vélocité des données entravée. Ce n’est pas un “data hub”.
Aujourd’hui, il vaut mieux partager et diffuser les données plutôt que les enfermer dans des silos. Des systèmes construits en vue de partager les données sont en outre fondamentalement différents de ceux construits pour stocker des données. Le temps est venu pour le secteur du stockage – y compris pour nous – de procurer une nouvelle architecture moderne. Nous espérons que le reste du secteur saisisse, lui aussi, cette opportunité.
Une lettre ouverte
signée PureStorage
(1) Deep Learning Scaling is Predictable, Empirically
(2) What Artificial Intelligence Can and Can’t Do Right Now – Harvard Business Review
(3) Nuts and Bolts of Applying Deep Learning
[ Retour au texte ]
Découvrez-nous sur Facebook
Suivez-nous sur Twitter
Retrouvez-nous sur LinkedIn
Régional-IT est affilié au portail d’infos Tribu Médias.