Plusieurs hôpitaux belges, en liaison ou non avec des universités et centres de recherche, commencent à s’intéresser de près au potentiel du “big data”. C’est par exemple le cas au CHU de Liège, en matière de “gérontechnologie” (gériatrie) et de conseil aux professionnels de la santé. Voir notre article.
{kind=link}
L’aide à la décision, mais cette fois au service des radiologues, fait l’objet d’un autre projet de recherche qui vient de démarrer en collaboration entre l’Université de Mons et l’Institut Jules Bordet.
Objectif: développer de nouveaux algorithmes permettant d’exploiter les informations contenues dans les clichés de radiologie. “L’imagerie médicale fournit une multitude d’images. En se basant sur les millions d’images que comporte l’importante base de données de scanners, avec des cas déjà diagnostiqués, il est possible de les structurer, de trouver de nouvelles méthodologies de recherche qui permettraient d’identifier des clichés intéressants à comparer avec les nouveaux clichés qui sont pris au fil des jours”, explique Saïd Mahmoudi, chargé de cours à l’UMons, spécialisé en analyse d’images dans les domaines médical et industriel.
“On dispose d’une grande masse de données (anonymisées) et de comptes-rendus mais qui ne sont pas exploités. Tout le travail d’analyse et de diagnostic effectué au fil du temps par les radiologues et spécialistes n’est pas exploité. Or, en se basant sur des techniques d’annotation automatique d’image et de reconnaissance d’images, il est possible de développer des solutions d’aide au diagnostic.”
Les ‘big data’ contre le ‘crabe’
OncoDNA, société de Gosselies, s’est elle spécialisée dans la “théranostique (contraction de thérapeutique et de diagnostic) du cancer”. Son ambition: démocratiser le séquençage haut débit afin de “prédire et de suivre la réponse [des patients] aux médicaments anti-cancéreux au travers d’une analyse génomique et anatomopathologique complète”.
Une idée des volumes de données en jeu? Le génome humain “est comme un livre subdivisé en 46 chapitres, que sont les chromosomes”, explique Michael Herman, directeur business development chez OncoDNA. “Chaque chapitre comporte une et une seule phrase, à savoir un molécule d’ADN, composée de 4 lettres – A, C, T ou G. Au total, notre “livre” comporte 3,4 milliard de lettres…”
{kind=link}
Le projet OncoDeep vise à séquencer les gènes qui représentent un intérêt pour l’étude et la lutte contre le cancer. Le défi? “Lire à de multiples reprises un nombre limité de gènes, afin de les analyser.” 50 gènes sont concernés dans le cas d’OncoDeep DX, 109 pour OncoDeep Clinical.
Et, d’emblée, même sur de “petites séries”, le big data est résolument au rendez-vous. 50 gènes représentent en effet un volume de… 22 méga-octets de données. 30 lectures d’un exome (voir définition en encadré ci-contre) normal – qui comporte 22.000 gènes -, donne un volume de 13 Go. 250 lectures d’un exome tumoral génère 125 Go de données.
Que dire alors de l’analyse d’un génome entier normal! 30 lectures donnent 100 Go; 250 lectures d’un génome tumoral font exploser le compteur… à 1 téra-octet.
Objectif d’OncoDeep: repérer les variants et les mutations des gènes et déduire les effets des variants. Autrement dit, les maladies. “Il s’agit de recourir à un système expert pour étudier les mutations, lier le gène à l’ensemble des études cliniques en cours dans le monde et aux différents traitements testés avec différentes molécules afin de construire une base de connaissances experte.”
Cytomine
Autre projet de R&D: Cytomine, cofinancé par la Région wallonne et hébergé à l’ULg. Parmi les partenaires du projet: la société Pepite, auteur de la plate-forme Web de ‘predictive analytics’ DATAmaestro.
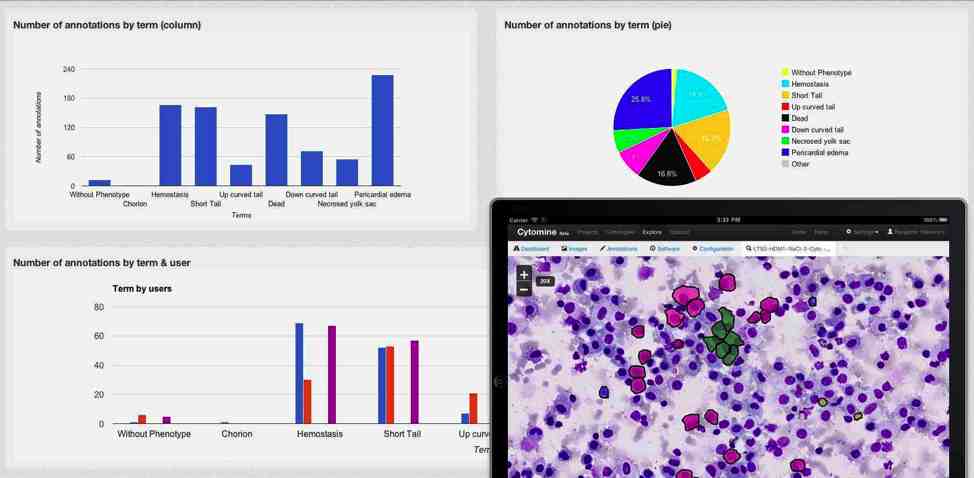
Le projet porte sur le développement d’une application Internet de “visualisation, d’annotation collaborative et d’analyse automatique d’images biologiques” avec recours à la fouille de données (“data mining”) permettant aux scientifiques de mieux évaluer de nouveaux traitements médicamenteux, de comprendre les processus biologiques et de faciliter les diagnostics.”
{kind=link}
Développée au départ pour l’analyse d’images cytologiques et histologiques (cancer du poumon et inflammations), l’application vise à multiplier les champs d’applications.
Philippe Mack (Pepite): “Les données de base existent mais ne sont pas exploitées dans leur pleine potentialité.”
La solution allie archivage d’images haute résolution de lames numérisées, leur analyse, des algorithmes de visualisation de données et de recherche d’images permettant d’accélérer les processus d’annotation, ainsi que des outils qui classent par exemple les cellules cancéreuses identifiées dans les coupes histologiques. “Les données de base existent mais ne sont pas exploitées dans leur pleine potentialité”, souligne Philippe Mack.
L’analyse des images se fait via le recours à des méthodes d’apprentissage automatique (machine learning) et de traitement qui exploitent les potentiels de systèmes distribués (architectures multi-coeurs et grappes de systèmes). Les algorithmes d’identification de types de tissus et de cellules peuvent être “entraînés” à détecter et décrire des “objets” biologiques pertinents.
A l’assaut de la génétique
En octobre dernier, des chercheurs d’iMinds et de la KU Leuven (Centre Stadius- Center for Dynamical Systems, Signal Processing and Data Analytics) annonçaient la mise au point d’un nouveau logiciel, baptisé eXtasy, orienté vers le traitement des données génétiques. En s’appuyant sur des techniques évoluées d’intelligence artificielle, eXtasy procède à une analyse automatique de vastes volumes de données génétiques pour en déduire “la cause la plus probable” d’une anomalie génétique ou d’une maladie héréditaire. Son efficacité (lisez: sa précision) serait de 20 fois supérieure à celle des méthodes analytiques existantes et ouvre la voie aux traitements personnalisés.
“Pas moins de 4 millions de différences ou mutations caractérisent les génomes de deux individus en bonne santé. La plupart de ces mutations sont inoffensives mais une seule mutation maligne peut suffire pour provoquer une anomalie génétique”, explique l’équipe de chercheurs.
“Les méthodes analytiques existantes ne sont tout simplement pas en mesure d’identifier rapidement et de manière fiable l’aiguille dans la botte de foin. […] eXtasy a recours à de l’intelligence artificielle évoluée pour combiner divers jeux de données complexes et d’en inférer un score global qui est le reflet de l’importance d’une mutation donnée dans le contexte d’une maladie déterminée.”
Ces jeux de données peuvent par exemple être des interactions entre protéines, des publications scientifiques, ou des relevés indiquant la dangerosité d’une mutation pour telle ou telle protéine.
Le développement du logiciel eXtasy a fait l’objet, en août 2013, d’un article dans la revue Nature – “eXtasy: variant prioritization by genomic data fusion”.
Propagation des épidémies
L’un des exemples les plus connus est celui du “Google Flu Trends” (nous y faisons référence dans notre article consacré à la qualité des données). L’exploitation des “big data” pourrait permettre de mieux détecter, anticiper, prédire la naissance et la propagation d’épidémies. Et ce, en combinant et analysant divers types d’informations et de sources: informations purement médicales, fournies par des professionnels, référentiels statistiques et historiques, analyse des échanges sur réseaux sociaux… Mais aussi par une mise en corrélation entre les maladies (ou leurs déclencheurs) et les données de déplacement des individus. Via, notamment, l’analyse de leurs données GSM.
Non seulement pour évaluer la propagation “en temps réel” mais, surtout, pour anticiper et prévenir. Sur base des données historiques et donc des schémas de “comportement” de populations ou groupes de population, il serait possible de prévoir où telle ou telle maladie risque de se disséminer. Cela permettrait donc de mener des campagnes d’information et de prévention plus efficace, de déployer préventivement des équipes médicales, de réapprovisionner correctement les stocks de médicaments, etc.
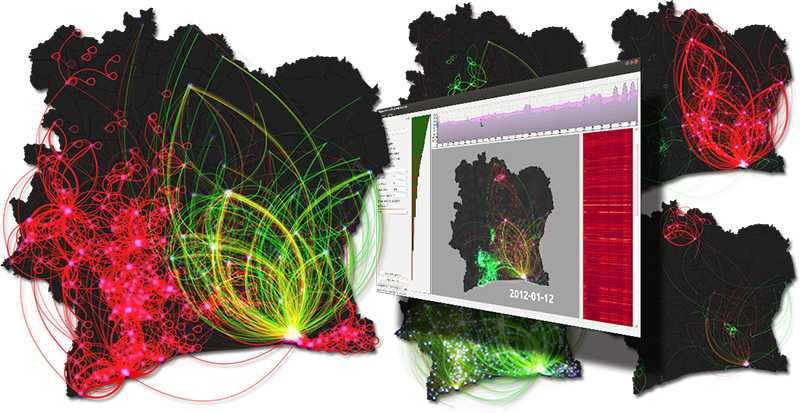
Document: D4D Challenge, Orange
{kind=link}
L’UCL a par exemple participé, aux côtés du MIT (Boston), à un concours de projets baptisé D4D Challenge (“data for development”). Le concours, de nature technologique, est organisé et sponsorisé par Orange.
L’idée: exploiter les données et statistiques générées par les réseaux de mobilophonie pour imaginer de nouvelles solutions ayant une finalité sociale, voire humanitaire, au bénéfice de populations moins privilégiées.
Le projet sur lequel des chercheurs de l’UCL ont planché vise à exploiter les données mobilophoniques afin d’endiguer la propagation de maladies et d’organiser des campagnes d’informations lors d’épidémies de grande envergure.
“Une campagne d’information pertinente, basée sur des conversations téléphoniques entre membres de groupes sociaux est un moyen efficace de lutter contre la propagation des maladies et épidémies.”
Les données mobiles sont suffisamment précises pour “tracer” les habitudes de déplacement des populations, de quoi élaborer des modèles pertinents. La précision sera d’autant plus grande que ces données pourront être croisées avec d’autres, portant sur l’identité sociale des individus, sur la nature communautaire, grégaire par zone, région, strate sociale, sur leurs interactions familiales, tribales, sociales…
Dans un domaine non lié à la santé, les chercheurs de l’UCL ont mené un autre projet dans le cadre de ce concours D4D. Il touche à l’analyse démographique en Afrique. Données servant à cette cartographie? Les données téléphoniques une fois encore. “L’analyse des comportements téléphoniques des gens permet de compléter des données démographiques officielles”, souligne Jean-Charles Delvenne, professeur adjoint à l’UCL et professeur à l’Ecole Polytechnique de Louvain. “Souvent, en effet, les recensements officiels sont incomplets ou effectués de manière trop irrégulière. Recourir aux données de mobilophonie permet de couvrir des zones qui sont mal couvertes par le système officiel. Ou plus vite. Cela permet aussi d’obtenir une vision des mouvements de population suite à une crise humanitaire.”
Découvrez-nous sur Facebook
Suivez-nous sur Twitter
Retrouvez-nous sur LinkedIn
Régional-IT est affilié au portail d’infos Tribu Médias.